SSE 实现实时数据推送

在现代Web应用中,实时通信成为了用户体验的重要组成部分。无论是社交媒体的即时通知,还是股票价格的实时更新,SSE(Server-Sent Events)作为一种轻量级的实时通信协议,能够帮助开发者实现高效的单向数据流推送。本篇博客将介绍如何使用Go语言实现一个基于SSE的实时消息推送系统。
什么是SSE?
Server-Sent Events (SSE) 是一种由服务器向浏览器单向推送实时更新的技术。与WebSocket不同,SSE建立在HTTP协议之上,适用于浏览器与服务器之间的单向数据传输。在许多场景中,SSE比WebSocket更加轻量,并且更易于实现,尤其是当你只需要从服务器向客户端推送数据时。
SSE的工作原理是:服务器通过HTTP连接将数据推送给客户端,客户端使用EventSource接口来接收数据流。每当服务器有新的数据时,客户端就会收到相应的更新。
为什么选择SSE?
- 简便易用:SSE的实现非常简单,客户端只需要一个EventSource对象,服务器只需按规范返回数据流。
- HTTP协议支持:SSE基于HTTP协议,因此不需要建立复杂的连接,它与现有的Web架构兼容。
- 自动重连:如果连接丢失,SSE会自动尝试重新连接,保证消息的持续性。
需求背景
在本篇博客中,我们将使用Go语言构建一个基于SSE的消息推送系统,前端将使用HTML和JavaScript与Go后端进行实时通信。
项目概述
在本项目中,我们将实现以下功能:
- 客户端:前端页面可以输入Token进行身份验证,连接到SSE服务器并接收实时消息。
- 服务器端:后端使用Go语言处理SSE连接,通过EventSource将数据推送到客户端。我们将使用JWT进行身份验证。
- 消息推送:后端将消息推送到与客户端建立的SSE连接。
技术栈
- Go 语言:后端使用Go实现,处理HTTP请求和SSE通信。
- HTML/JavaScript:前端实现,负责显示消息并与后端进行交互。
后端实现
在后端实现中,我们将分为几个主要部分:
- Client和ClientManager:管理客户端连接。
- SSE连接处理:处理客户端的SSE连接请求。
- 消息发送:通过SendMessage方法将消息推送到客户端。
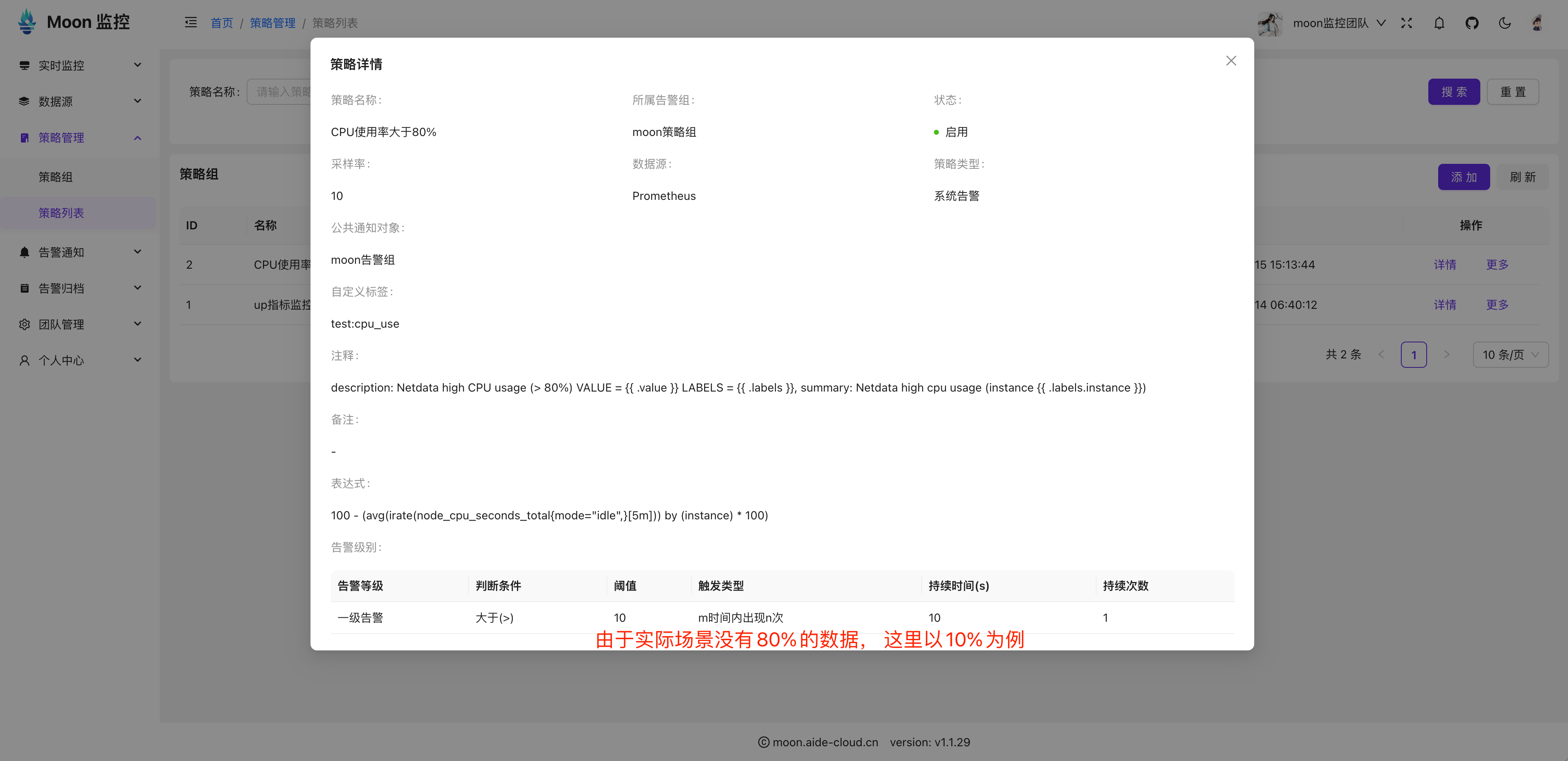
1. Client与ClientManager的实现
首先,我们需要定义Client和ClientManager结构体,分别用于表示每一个客户端和管理所有连接的客户端。
type Client struct {
ID uint32
Send chan []byte
}
type ClientManager struct {
clients *safety.Map[uint32, *Client]
}
- Client:每个客户端都有一个唯一的ID和一个用于发送消息的通道Send。
- ClientManager:管理所有连接的客户端,提供方法来添加、删除和获取客户端。
// NewClientManager 创建新的ClientManager
func NewClientManager() *ClientManager {
return &ClientManager{
clients: safety.NewMap[uint32, *Client](),
}
}
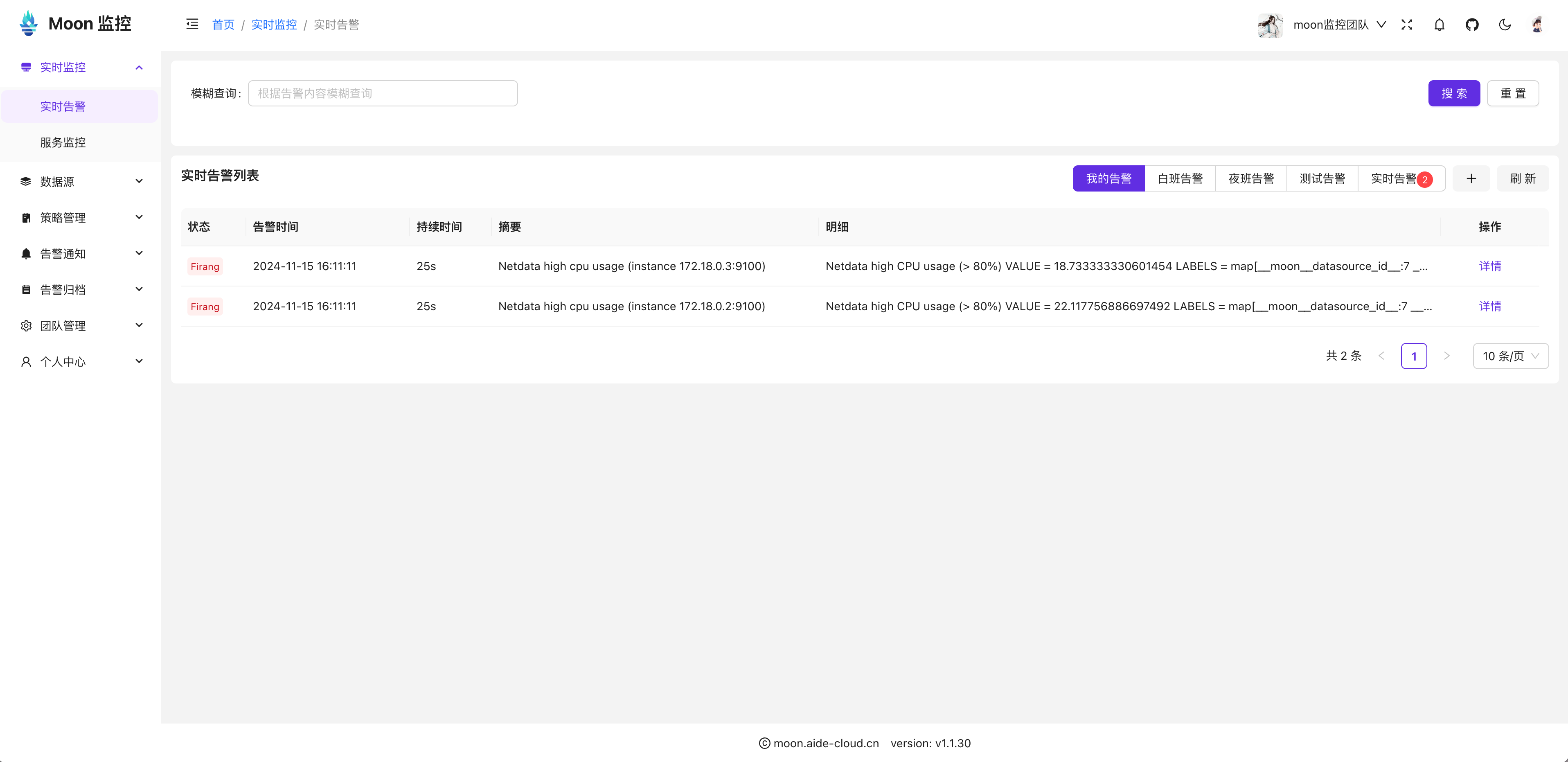
2. 处理SSE连接:NewSSEHandler
NewSSEHandler函数处理客户端的SSE连接。当客户端请求连接时,我们会验证JWT Token并将客户端添加到ClientManager中。
func NewSSEHandler(clientManager *ClientManager) http.HandlerFunc {
return func(w http.ResponseWriter, r *http.Request) {
token := r.URL.Query().Get("token")
if token == "" {
http.Error(w, "token is required", http.StatusBadRequest)
return
}
// 设置HTTP头部,指定这是一个SSE连接
w.Header().Set("Content-Type", "text/event-stream")
w.Header().Set("Cache-Control", "no-cache")
w.Header().Set("Connection", "keep-alive")
claims, ok := middleware.ParseJwtClaimsFromToken(strings.TrimPrefix(token, "Bearer "))
if !ok {
http.Error(w, "token is invalid", http.StatusUnauthorized)
return
}
client := NewClient(claims.GetUser())
clientManager.AddClient(client)
defer func() {
clientManager.RemoveClient(client.ID)
}()
go client.WriteSSE(w)
<-r.Context().Done()
log.Infof("client %d disconnected", client.ID)
}
}
在这段代码中,我们:
- 验证Token并解析JWT。
- 如果Token有效,创建一个Client对象并将其加入ClientManager。
- 为每个客户端开启一个goroutine来执行WriteSSE,持续推送数据流。
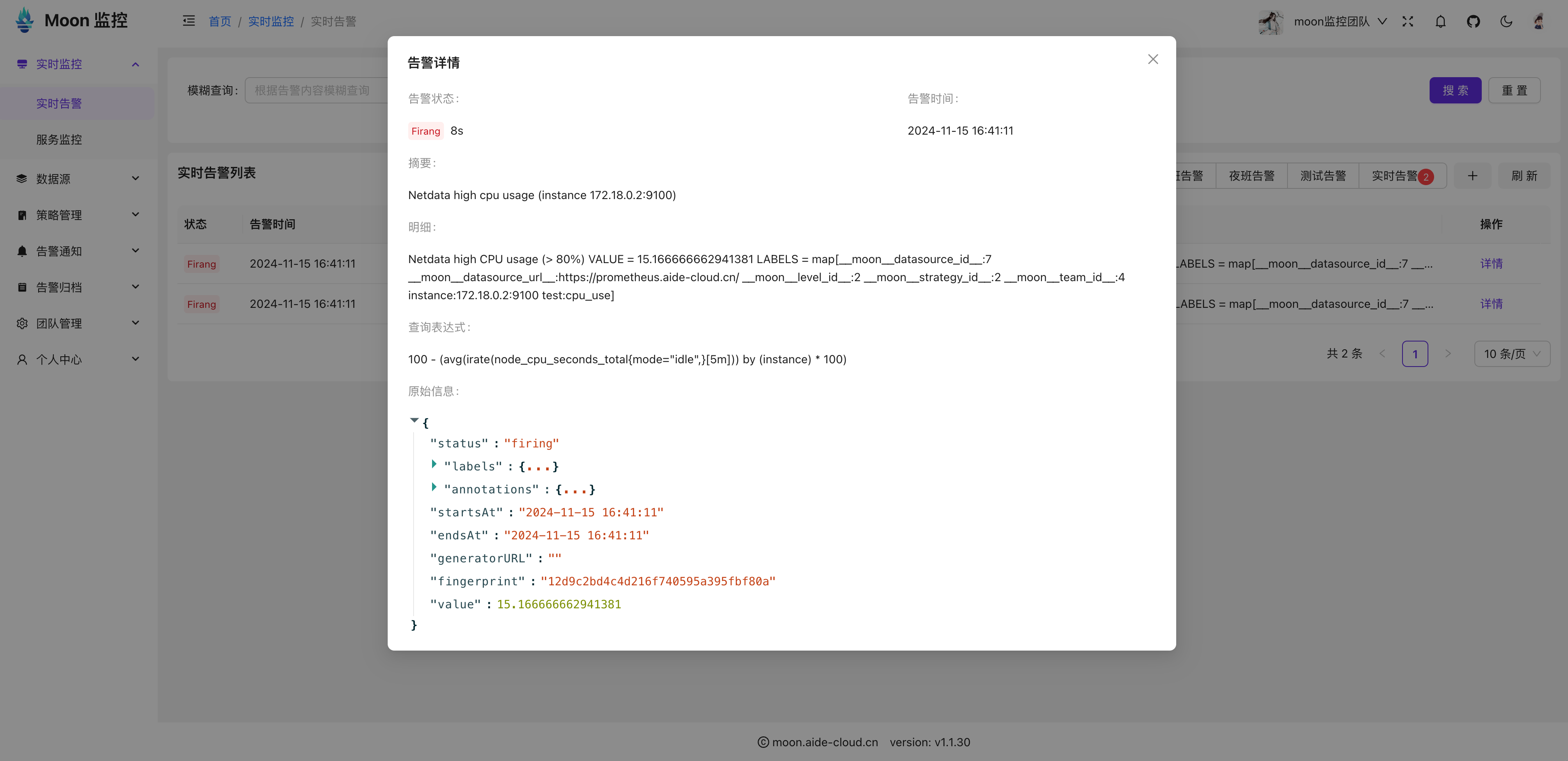
3. 消息推送:WriteSSE和SendMessage
WriteSSE方法负责向客户端推送消息流,使用HTTP流式响应将数据发送给客户端。
func (c *Client) WriteSSE(w http.ResponseWriter) {
defer after.RecoverX()
flusher, ok := w.(http.Flusher)
if !ok {
log.Errorw("err", "Streaming unsupported!")
http.Error(w, "Streaming unsupported!", http.StatusInternalServerError)
return
}
log.Debugw("msg", "listen sse client")
for data := range c.Send {
log.Debugw("WriteSSE", string(data))
_, _ = fmt.Fprintf(w, "data: %s\n\n", string(data))
flusher.Flush()
}
log.Debugw("WriteSSE", "data: [DONE]")
}
func (c *Client) SendMessage(message string) (err error) {
defer func() {
if r := recover(); r != nil {
err = fmt.Errorf("send message error: %v", r)
}
}()
c.Send <- []byte(message)
return
}
- WriteSSE:接收客户端请求后,持续推送消息流,直到连接断开。
- SendMessage:向客户端发送消息,通过Send通道将消息发送给客户端。
前端实现
前端部分非常简洁,使用EventSource对象建立与后端的SSE连接。
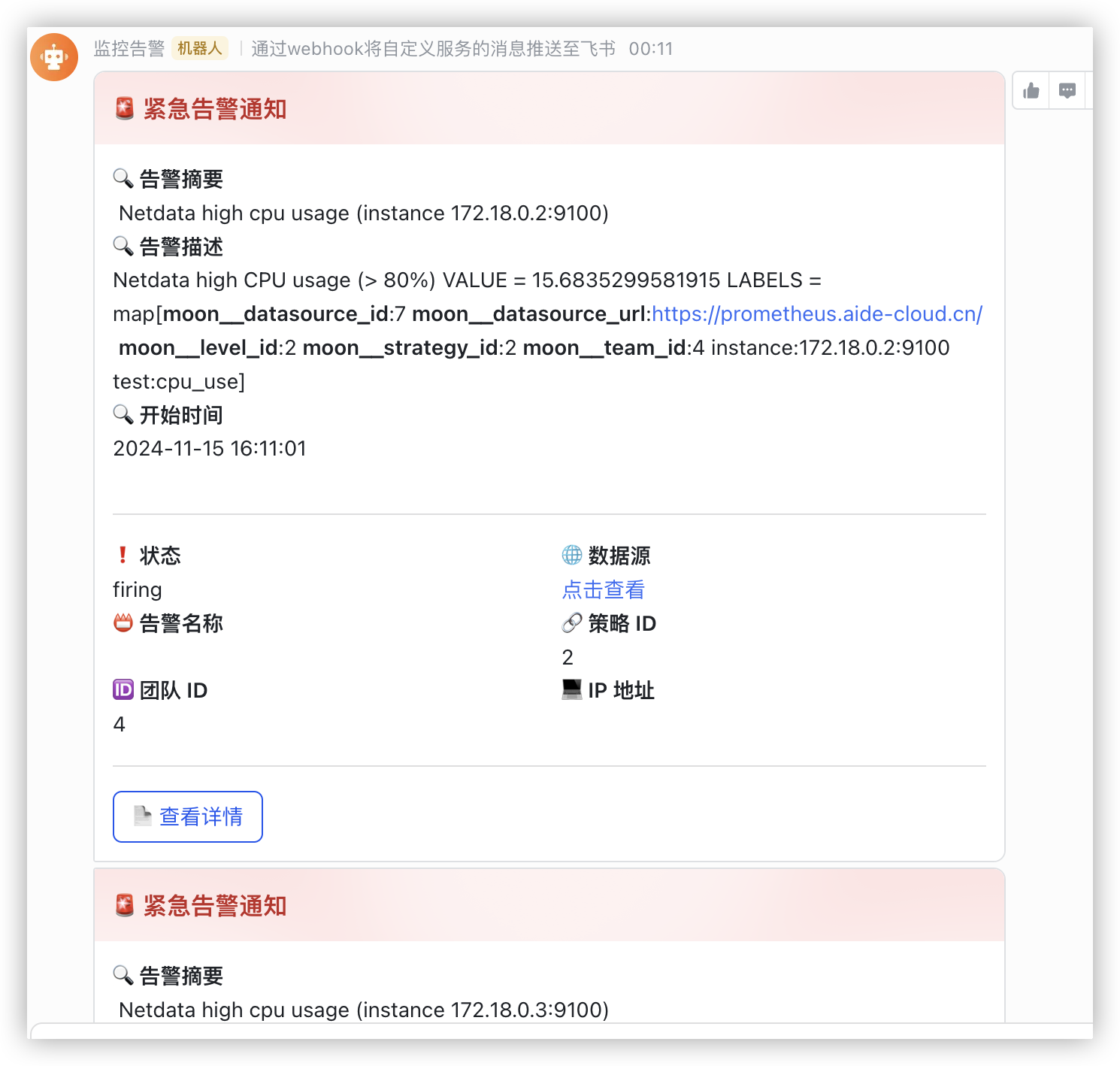
1. 连接到SSE服务器
function connectToSSE() {
const token = document.getElementById('token').value;
if (!token) {
alert("Please enter a Token.");
return;
}
// 创建一个EventSource对象,连接到服务器的SSE端点
const url = new URL(`http://localhost:9999/events`);
url.searchParams.set("token", token);
eventSource = new EventSource(url.toString());
eventSource.onmessage = function(event) {
const messagesDiv = document.getElementById('messages');
const newMessage = document.createElement('div');
newMessage.textContent = `New message: ${event.data}`;
messagesDiv.appendChild(newMessage);
messagesDiv.scrollTop = messagesDiv.scrollHeight; // 自动滚动到最新消息
};
eventSource.onerror = function() {
alert("Error connecting to server.");
eventSource.close();
};
eventSource.onopen = function() {
console.log("SSE connection established.");
};
}
在此代码中,前端通过输入Token与后端建立连接,并使用EventSource接收实时消息。当消息到达时,自动将其显示在页面上。
2. 发送消息
function sendMessage() {
const message = document.getElementById('message').value;
if (!message) {
alert("Please enter a message.");
return;
}
fetch(`/msg?msg=${message}`, {
method: 'GET',
headers: {
'Authorization': 'Bearer ' + document.getElementById('token').value,
}
});
}
用户输入消息后,通过GET请求将消息发送到后端,后端根据Token验证身份并将消息推送到对应的客户端。
总结与优化建议
1. 优点
- 简单易用:SSE相较于WebSocket实现更加简单,不需要处理双向通信。
- 高效:对于只需要单向推送数据的场景,SSE非常高效,并且可以轻松处理数千个并发连接。
- 自动重连:SSE内建自动重连机制,保证了连接的稳定性。
2. 优化建议
- 连接管理:使用Redis或其他分布式缓存来管理多个实例之间的客户端连接,支持横向扩展。
- Token验证:目前通过URL传递Token,可以进一步加强安全性,通过HTTP头部传递Token。
通过SSE,开发者可以轻松实现实时推送功能,而Go语言则提供了高效的并发处理能力,非常适合用于构建这种类型的服务。